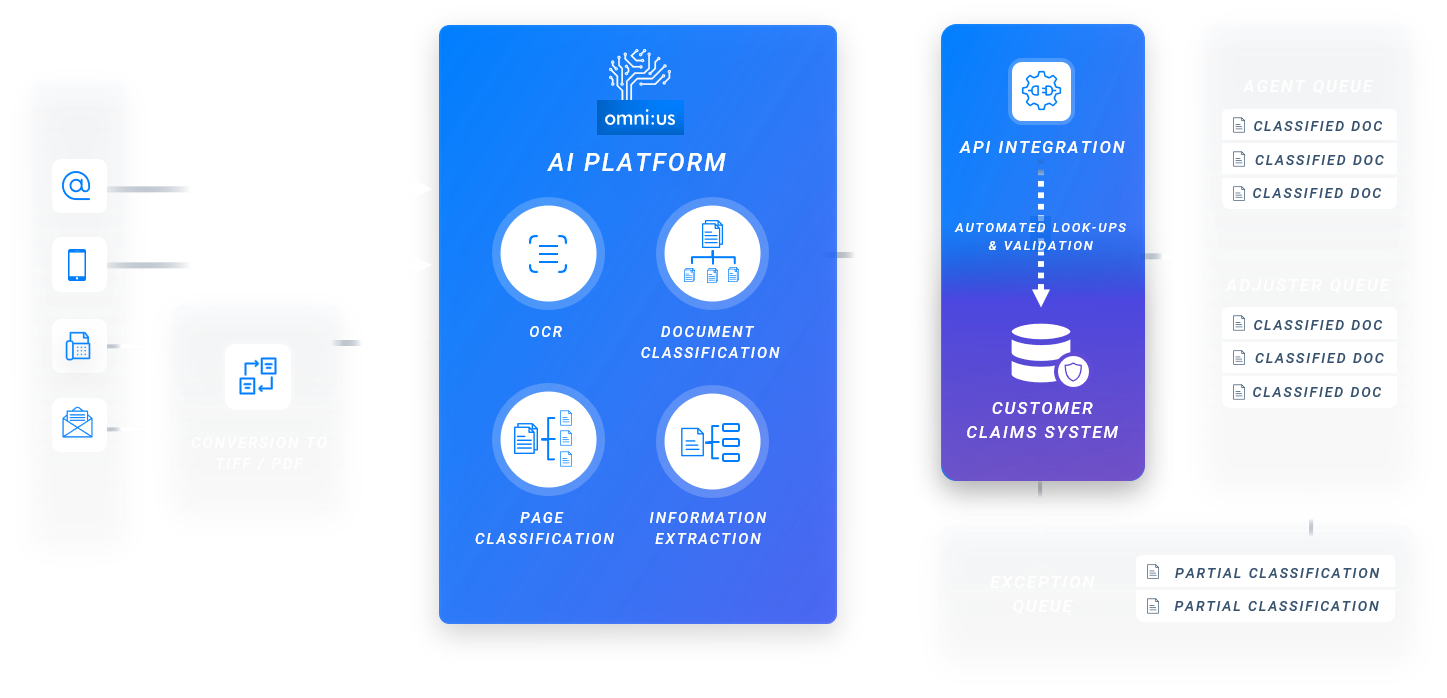
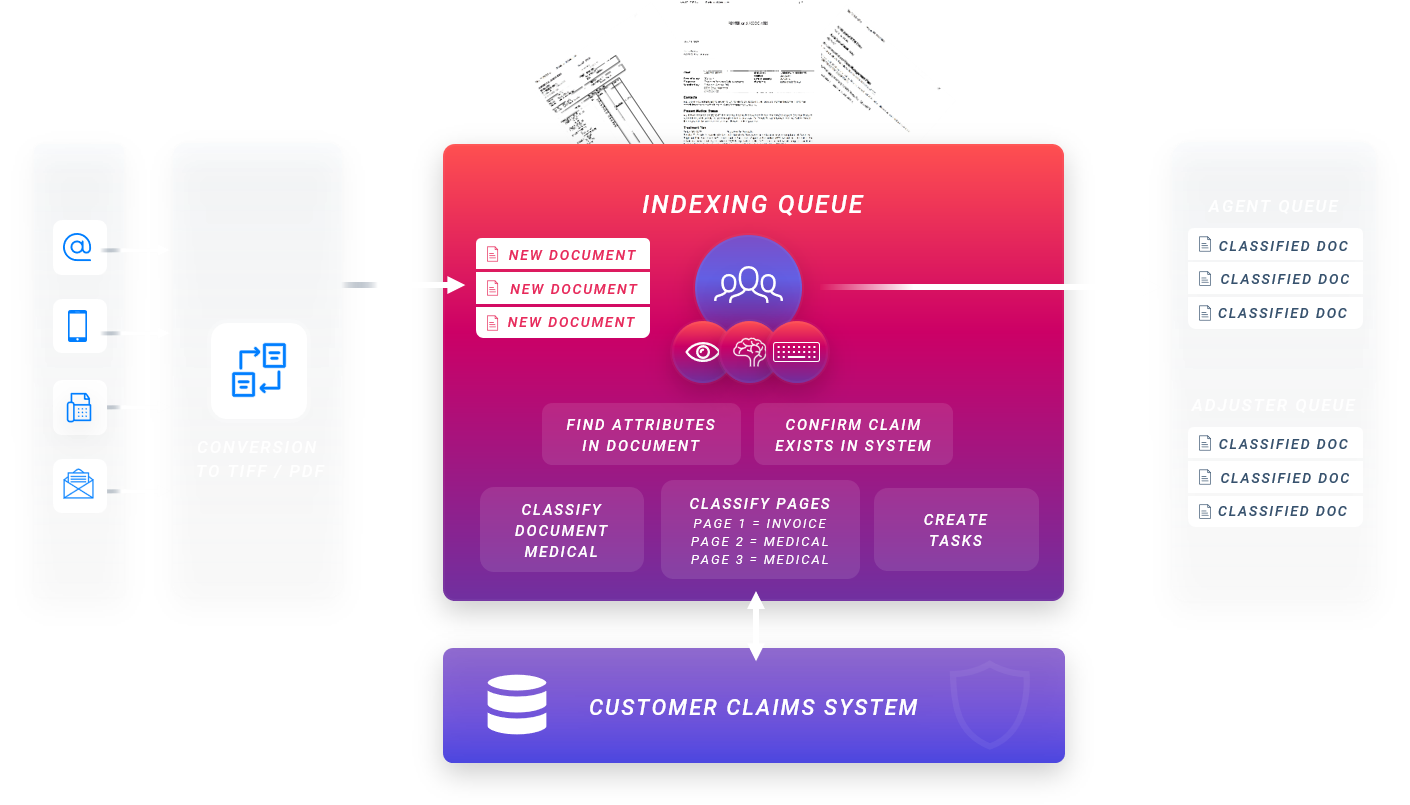
A Fortune 500 insurer wanted to reduce inefficiencies and errors caused by manual document classification and data extraction. omni:us automated the indexation and processing of 100.000 unstructured workers’ compensation claims notification documents provided per day via physical documents, letters, and e-mails.
Issue
Ineffective processes and lack of technology applied demands a highly manual and personnel intensive claims file creation process
Complex business rules on document classifications causing false routing and processing loops
Insufficient and manual data structuring procedures frequently cause errors during data extraction resulting in additional processing loops
Incomplete manual data capturing after document intake results in a significant data loss between indexing (registration of claim) and adjustment (claim handling) again increasing processing loops
Impact
Decreased average claims processing time
Reduced complexity of business rules for document classes from 32 to 16 becoming MECE and eliminating redundancies
Lowered amount of document misclassifications
Redeployed employees from manual steps to sophisticated work
Solution
Standardized document classification guidelines and redefined relevant data extraction points
Trained AI to automatically classify incoming documents correctly
Extracted relevant data from incoming documents relevant for the overall claims handling process
Introduced automatic filing and assignment of claims files directly into underlying core claims handling system
comparison
Claims indexation
omni:us
Manual
AI-Powered Document Processing
DOCUMENT CLASSIFICATION
Classify documents or pages into predefined categories. Based on visual and textual information. Use of state of the art deep learning based classification methods.
INFORMATION EXTRACTION
Extract information from semistructured documents using state using advanced named entity recognition and end2end information extraction techniques.
HANDWRITTEN TEXT RECOGNITION
Extract information from handwritten forms using language and writer independent handwritten text recognition technology.
FREE TEXT INTERPRETATION
Interpret unstructured documents and text with text classification, named entity recognition, language models and question answering techniques.